
Big data is often stored in a data lake. While data warehouses are commonly built on relational databases and contain structured data only, data lakes can support various data types and typically are based on Hadoop clusters, cloud object storage services, NoSQL databases or other big data platforms.
Many big data environments combine multiple systems in a distributed architecture; for example, a central data lake might be integrated with other platforms, including relational databases or a data warehouse. The data in big data systems may be left in its raw form and then filtered and organized as needed for particular analytics uses. In other cases, it's preprocessed using data mining tools and data preparation software so it's ready for applications that are run regularly.
Big data processing places heavy demands on the underlying compute infrastructure. The required computing power often is provided by clustered systems that distribute processing workloads across hundreds or thousands of commodity servers, using technologies like Hadoop and the Spark processing engine.
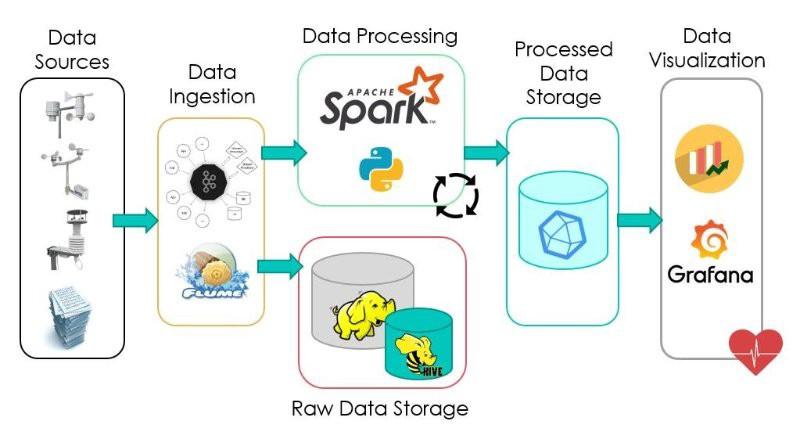
Getting that kind of processing capacity in a cost-effective way is a challenge. As a result, the cloud is a popular location for big data systems. Organizations can deploy their own cloud-based systems or use managed big-data-as-a-service offerings from cloud providers. Cloud users can scale up the required number of servers just long enough to complete big data analytics projects. The business only pays for the storage and compute time it uses, and the cloud instances can be turned off until they're needed again.